


Introduction
The FastMKS algorithm (fast exact max-kernel search) is a recent algorithm proposed in the following papers:
Given a set of query points  and a set of reference points
and a set of reference points 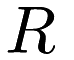 , the FastMKS algorithm is a fast dual-tree (or single-tree) algorithm which finds
, the FastMKS algorithm is a fast dual-tree (or single-tree) algorithm which finds
![\[ \arg\max_{p_r \in R} K(p_q, p_r) \]](form_199.png)
for all points 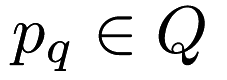 and for some Mercer kernel
and for some Mercer kernel 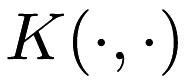 . A Mercer kernel is a kernel that is positive semidefinite; these are the classes of kernels that can be used with the kernel trick. In short, the positive semidefiniteness of a Mercer kernel means that any kernel matrix (or Gram matrix) created on a dataset must be positive semidefinite.
. A Mercer kernel is a kernel that is positive semidefinite; these are the classes of kernels that can be used with the kernel trick. In short, the positive semidefiniteness of a Mercer kernel means that any kernel matrix (or Gram matrix) created on a dataset must be positive semidefinite.
The FastMKS algorithm builds trees on the datasets and in such a way that explicit representation of the points in the kernel space is unnecessary, by using cover trees (mlpack::tree::CoverTree). This allows the algorithm to be run, for instance, on string kernels, where there is no sensible explicit representation. The mlpack implementation allows any type of tree that does not require an explicit representation to be used. For more details, see the paper.
At the time of this writing there is no other fast algorithm for exact max-kernel search. mlpack implements both single-tree and dual-tree fast max-kernel search.
mlpack provides:
- a simple command-line executable to run FastMKS
- a C++ interface to run FastMKS
Table of Contents
A list of all the sections this tutorial contains.
- Introduction
- Table of Contents
- Command-line FastMKS (mlpack_fastmks)
- The 'FastMKS' class
- Writing a custom kernel for FastMKS
- Using other tree types for FastMKS
- Running FastMKS on objects
- Further documentation
Command-line FastMKS (mlpack_fastmks)
mlpack provides a command-line program, mlpack_fastmks, which is used to perform FastMKS on a given query and reference dataset. It supports numerous different types of kernels:
- linear kernel
- polynomial kernel
- cosine distance
- Gaussian kernel
- Epanechnikov kernel
- triangular kernel
- hyperbolic tangent kernel
Note that when a shift-invariant kernel is used, the results will be the same as nearest neighbor search, so KNN may be a better option. A shift-invariant kernel is a kernel that depends only on the distance between the two input points. The Gaussian kernel, Epanechnikov kernel, and triangular kernel are instances of shift-invariant kernels. The paper contains more details on this situation. The mlpack_fastmks executable still provides these kernels as options, though.
The following examples detail usage of the mlpack_fastmks program. Note that you can get documentation on all the possible parameters by typing:
FastMKS with a linear kernel on one dataset
If only one dataset is specified (with -r or –reference_file), the reference dataset is taken to be both the query and reference datasets. The example below finds the 4 maximum kernels of each point in dataset.csv, using the default linear kernel.
When the operation completes, the values of the kernels are saved in products.csv and the indices of the points which give the maximum kernels are saved in indices.csv.
We can see in this example that for point 0, the point with maximum kernel value is point 762, with a kernel value of 1.622165. For point 3, the point with third largest kernel value is point 863, with a kernel value of 1.0669.
FastMKS on a reference and query dataset
The query points may be different than the reference points. To specify a different query set, the -q (or –query_file) option is used, as in the example below.
FastMKS with a different kernel
The mlpack_fastmks program offers more than just the linear kernel. Valid options are 'linear', 'polynomial', 'cosine', 'gaussian', 'epanechnikov', 'triangular' and 'hyptan' (the hyperbolic tangent kernel). Note that the hyperbolic tangent kernel is provably not a Mercer kernel but is positive semidefinite on most datasets and is commonly used as a kernel. Note also that the Gaussian kernel and other shift-invariant kernels give the same results as nearest neighbor search (see NeighborSearch tutorial (k-nearest-neighbors)).
The kernel to use is specified with the -K (or –kernel) option. The example below uses the cosine similarity as a kernel.
Using single-tree search or naive search
In some cases, it may be useful to not use the dual-tree FastMKS algorithm. Instead you can specify the –single option, indicating that a tree should be built only on the reference set, and then the queries should be processed in a linear scan (instead of in a tree). Alternately, the -N (or –naive) option makes the program not build trees at all and instead use brute-force search to find the solutions.
The example below uses single-tree search on two datasets with the linear kernel.
The example below uses naive search on one dataset.
Parameters for alternate kernels
Many of the alternate kernel choices have parameters which can be chosen; these are detailed in this section.
-w(–bandwidth): this sets the bandwidth of the kernel, and is applicable to the'gaussian','epanechnikov', and'triangular'kernels. This is the "spread" of the kernel.-d(–degree): this sets the degree of the polynomial kernel (the power to which the result is raised). It is only applicable to the'polynomial'kernel.-o(–offset): this sets the offset of the kernel, for the'polynomial'and'hyptan'kernel. See the polynomial kernel documentation and the hyperbolic tangent kernel documentation for more information.-s(–scale): this sets the scale of the kernel, and is only applicable to the'hyptan'kernel. See the hyperbolic tangent kernel documentation for more information.
Saving a FastMKS model/tree
The mlpack_fastmks program also supports saving a model built on a reference dataset (this model includes the tree, the kernel, and the search parameters). The –output_model_file or -M option allows one to save these parameters to disk for later usage. An example is below:
This example builds a tree on the dataset in reference_set.csv using the cosine similarity kernel, and saves the resulting model to fastmks_model.xml. This model may then be used in later calls to the mlpack_fastmks program.
Loading a FastMKS model for further searches
Supposing that a FastMKS model has been saved with the –output_model_file or -M parameter, that model can then be later loaded in subsequent calls to the mlpack_fastmks program, using the –input_model_file or -m option. For instance, with a model saved in fastmks_model.xml and a query set in query_set.csv, we can find 3 max-kernel candidates, saving to indices.csv and kernels.csv:
Loading a model as opposed to building a model is advantageous because the reference tree is already built. So, among other situations, this could be useful in the setting where many different query sets (or many different values of k) will be used.
Note that the kernel cannot be changed in a saved model without rebuilding the model entirely.
The 'FastMKS' class
The FastMKS<> class offers a simple API for use within C++ applications, and allows further flexibility in kernel choice and tree type choice. However, FastMKS<> has no default template parameter for the kernel type – that must be manually specified. Choices that mlpack provides include:
- mlpack::kernel::LinearKernel
- mlpack::kernel::PolynomialKernel
- mlpack::kernel::CosineDistance
- mlpack::kernel::GaussianKernel
- mlpack::kernel::EpanechnikovKernel
- mlpack::kernel::TriangularKernel
- mlpack::kernel::HyperbolicTangentKernel
- mlpack::kernel::LaplacianKernel
- mlpack::kernel::PSpectrumStringKernel
The following examples use kernels from that list. Writing your own kernel is detailed in the next section. Remember that when you are using the C++ interface, the data matrices must be column-major. See Matrices in mlpack for more information.
FastMKS on one dataset
Given only a reference dataset, the following code will run FastMKS with k set to 5.
FastMKS with a query and reference dataset
In this setting we have both a query and reference dataset. We search for 10 maximum kernels.
FastMKS with an initialized kernel
Often, kernels have parameters which need to be specified. FastMKS<> has constructors which take initialized kernels. Note that temporary kernels cannot be passed as an argument. The example below initializes a PolynomialKernel object and then runs FastMKS with a query and reference dataset.
The syntax for running FastMKS with one dataset and an initialized kernel is very similar:
FastMKS with an already-created tree
By default, FastMKS<> uses the cover tree datastructure (see mlpack::tree::CoverTree). Sometimes, it is useful to modify the parameters of the cover tree. In this scenario, a tree must be built outside of the constructor, and then passed to the appropriate FastMKS<> constructor. An example on just a reference dataset is shown below, where the base of the cover tree is modified.
We also use an instantiated kernel, but because we are building our own tree, we must use IPMetric so that our tree is built on the metric induced by our kernel function.
The syntax is similar for the case where different query and reference datasets are given; but trees for both need to be built in the manner specified above. Be sure to build both trees using the same metric (or at least a metric with the exact same parameters).
Writing a custom kernel for FastMKS
While mlpack provides some number of kernels in the mlpack::kernel namespace, it is easy to create a custom kernel. To satisfy the KernelType policy, a class must implement the following methods:
The template parameter VecType is helpful (but not necessary) so that the kernel can be used with both sparse and dense matrices (arma::sp_mat and arma::mat).
Using other tree types for FastMKS
The use of the cover tree (see CoverTree) is not necessary for FastMKS, although it is the default tree type. A different type of tree can be specified with the TreeType template parameter. However, the tree type is required to have FastMKSStat as the StatisticType, and for FastMKS to work, the tree must be built only on kernel evaluations (or distance evaluations in the kernel space via IPMetric::Evaluate()).
Below is an example where a custom tree class, CustomTree, is used as the tree type for FastMKS. In this example FastMKS is only run on one dataset.
Running FastMKS on objects
FastMKS has a lot of utility on objects which are not representable in some sort of metric space. These objects might be strings, graphs, models, or other objects. For these types of objects, questions based on distance don't really make sense. One good example is with strings. The question "how far is 'dog' from 'Taki Inoue'?" simply doesn't make sense. We can't have a centroid of the terms 'Fritz', 'E28', and 'popsicle'.
However, what we can do is define some sort of kernel on these objects. These kernels generally correspond to some similarity measure, with one example being the p-spectrum string kernel (see mlpack::kernel::PSpectrumStringKernel). Using that, we can say "how similar is 'dog' to 'Taki Inoue'?" and get an actual numerical result by evaluating K('dog', 'Taki Inoue') (where K is our p-spectrum string kernel).
The only requirement on these kernels is that they are positive definite kernels (or Mercer kernels). For more information on those details, refer to the FastMKS paper.
Remember that FastMKS is a tree-based method. But trees like the binary space tree require centroids – and as we said earlier, centroids often don't make sense with these types of objects. Therefore, we need a type of tree which is built exclusively on points in the dataset – those are points which we can evaluate our kernel function on. The cover tree is one example of a type of tree satisfying this condition; its construction will only call the kernel function on two points that are in the dataset.
But, we have one more problem. The CoverTree class is built on arma::mat objects (dense matrices). Our objects, however, are not necessarily representable in a column of a matrix. To use the example we have been using, strings cannot be represented easily in a matrix because they may all have different lengths.
The way to work around this problem is to create a "fake" data matrix which simply holds indices to objects. A good example of how to do this is detailed in the documentation for the PSpectrumStringKernel.
In short, the trick is to make each data matrix one-dimensional and containing linear indices:
Then, when Evaluate() is called on the kernel function, the parameters will be two one-dimensional vectors that simply contain indices to objects. The example below details the process a little better:
As written earlier, the documentation for PSpectrumStringKernel is a good place to consult for further reference on this. That kernel uses two dimensional indices; one dimension represents the index of the string, and the other represents whether it is referring to the query set or the reference set. If your kernel is meant to work on separate query and reference sets, that strategy should be considered.
Further documentation
For further documentation on the FastMKS class, consult the complete API documentation.