


Introduction
Nearest-neighbors search is a common machine learning task. In this setting, we have a query and a reference dataset. For each point in the query dataset, we wish to know the 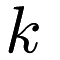 points in the reference dataset which are closest to the given query point.
points in the reference dataset which are closest to the given query point.
Alternately, if the query and reference datasets are the same, the problem can be stated more simply: for each point in the dataset, we wish to know the nearest points to that point.
mlpack provides:
- a simple command-line executable to run nearest-neighbors search (and furthest-neighbors search)
- a simple C++ interface to perform nearest-neighbors search (and furthest-neighbors search)
- a generic, extensible, and powerful C++ class (NeighborSearch) for complex usage
Table of Contents
A list of all the sections this tutorial contains.
- Introduction
- Table of Contents
- Command-Line 'mlpack_knn'
- The 'KNN' class
- The extensible 'NeighborSearch' class
- Further documentation
Command-Line 'mlpack_knn'
The simplest way to perform nearest-neighbors search in mlpack is to use the mlpack_knn executable. This program will perform nearest-neighbors search and place the resultant neighbors into one file and the resultant distances into another. The output files are organized such that the first row corresponds to the nearest neighbors of the first query point, with the first column corresponding to the nearest neighbor, and so forth.
Below are several examples of simple usage (and the resultant output). The -v option is used so that output is given. Further documentation on each individual option can be found by typing
One dataset, 5 nearest neighbors
Convenient program timers are given for different parts of the calculation at the bottom of the output, as well as the parameters the simulation was run with. Now, if we look at the output files:
So, the nearest neighbor to point 0 is point 862, with a distance of 5.986076164057e-02. The second nearest neighbor to point 0 is point 344, with a distance of 7.664920518084e-02. The third nearest neighbor to point 5 is point 751, with a distance of 1.085637706630e-01.
Query and reference dataset, 10 nearest neighbors
One dataset, 3 nearest neighbors, leaf size of 15 points
Further documentation on options should be found by using the –help option.
The 'KNN' class
The 'KNN' class is, specifically, a typedef of the more extensible NeighborSearch class, querying for nearest neighbors using the Euclidean distance.
Using the KNN class is particularly simple; first, the object must be constructed and given a dataset. Then, the method is run, and two matrices are returned: one which holds the indices of the nearest neighbors, and one which holds the distances of the nearest neighbors. These are of the same structure as the output –neighbors_file and –distances_file for the CLI interface (see above). A handful of examples of simple usage of the KNN class are given below.
5 nearest neighbors on a single dataset
The output of the search is stored in resultingNeighbors and resultingDistances.
10 nearest neighbors on a query and reference dataset
Naive (exhaustive) search for 6 nearest neighbors on one dataset
This example uses the O(n^2) naive search (not the tree-based search).
Needless to say, naive search can be very slow...
The extensible 'NeighborSearch' class
The NeighborSearch class is very extensible, having the following template arguments:
By choosing different components for each of these template classes, a very arbitrary neighbor searching object can be constructed. Note that each of these template parameters have defaults, so it is not necessary to specify each one.
SortPolicy policy class
The SortPolicy template parameter allows specification of how the NeighborSearch object will decide which points are to be searched for. The mlpack::neighbor::NearestNeighborSort class is a well-documented example. A custom SortPolicy class must implement the same methods which NearestNeighborSort does:
The mlpack::neighbor::FurthestNeighborSort class is another implementation, which is used to create the 'KFN' typedef class, which finds the furthest neighbors, as opposed to the nearest neighbors.
MetricType policy class
The MetricType policy class allows the neighbor search to take place in any arbitrary metric space. The mlpack::metric::LMetric class is a good example implementation. A MetricType class must provide the following functions:
Internally, the NeighborSearch class keeps an instantiated MetricType class (which can be given in the constructor). This is useful for a metric like the Mahalanobis distance (mlpack::metric::MahalanobisDistance), which must store state (the covariance matrix). Therefore, you can write a non-static MetricType class and use it seamlessly with NeighborSearch.
For more information on the MetricType policy, see the documentation here.
MatType policy class
The MatType template parameter specifies the type of data matrix used. This type must implement the same operations as an Armadillo matrix, and so standard choices are arma::mat and arma::sp_mat.
TreeType policy class
The NeighborSearch class allows great extensibility in the selection of the type of tree used for search. This type must follow the typical mlpack TreeType policy, documented here.
Typical choices might include mlpack::tree::KDTree, mlpack::tree::BallTree, mlpack::tree::StandardCoverTree, mlpack::tree::RTree, or mlpack::tree::RStarTree. It is easily possible to make your own tree type for use with NeighborSearch; consult the TreeType documentation for more details.
An example of using the NeighborSearch class with a ball tree is given below.
TraverserType policy class
The last template parameter the NeighborSearch class offers is the TraverserType class. The TraverserType class holds the strategy used to traverse the trees in either single-tree or dual-tree search mode. By default, it is set to use the default traverser of the given TreeType (which is the member TreeType::DualTreeTraverser).
This class must implement the following two methods:
The RuleType class provides the following functions for use in the traverser:
Note also that any traverser given must satisfy the definition of a pruning dual-tree traversal given in the paper "Tree-independent dual-tree algorithms".
Further documentation
For further documentation on the NeighborSearch class, consult the complete API documentation.