


Introduction
Trees are an important data structure in mlpack and are used in a number of the machine learning algorithms that mlpack implements. Often, the use of trees can allow significant acceleration of an algorithm; this is generally done by pruning away large parts of the tree during computation.
Most mlpack algorithms that use trees are not tied to a specific tree but instead allow the user to choose a tree via the TreeType template parameter. Any tree passed as a TreeType template parameter will need to implement a certain set of functions. In addition, a tree may optionally specify some traits about itself with the TreeTraits trait class.
This document aims to clarify the abstractions underlying mlpack trees, list and describe the required functionality of the TreeType policy, and point users towards existing types of trees. A table of contents is below:
- Introduction
- What is a tree?
- Template parameters required by the TreeType policy
- The TreeType API
- Rigorous API documentation
- The TreeTraits trait class
- A list of trees in mlpack and more information
Although this document is long, there may still be errors and unclear areas. If you are having trouble understanding anything, please get in touch on Github or on the mailing list and someone will help you (and possibly update the documentation afterwards).
What is a tree?
In mlpack, we assume that we have some sort of data matrix, which might be sparse or dense (that is, it could be of type arma::mat or arma::sp_mat, or any variant that implements the Armadillo API). This data matrix corresponds to a collection of points in some space (usually a Euclidean space). A tree is a way of organizing this data matrix in a hierarchical manner—so, points that are nearby should lie in similar nodes.
We can rigorously define what a tree is, using the definition of space tree introduced in the following paper:
The definition is:
A space tree on a dataset 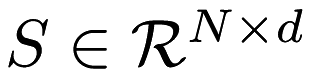 is an undirected, connected, acyclic, rooted simple graph with the following properties:
is an undirected, connected, acyclic, rooted simple graph with the following properties:
- Each node (or vertex) holds a number of points (possibly zero) and is connected to one parent node and a number of child nodes (possibly zero).
- There is one node in every space tree with no parent; this is the root node of the tree.
- Each point in
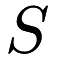 is contained in at least one node.
is contained in at least one node. - Each node corresponds to some subset of
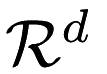 that contains each point in the node and also the subsets that correspond to each child of the node.
that contains each point in the node and also the subsets that correspond to each child of the node.
This is really a quite straightforward definition: a tree is hierarchical, and each node corresponds to some region of the input space. Each node may have some number of children, and may hold some number of points. However, there is an important terminology distinction to make: the term points held by a node has a different meaning than the term descendant points held by a node. The points held in a node are just that—points held only in the node. The descendant points of a node are the combination of the points held in a node with the points held in the node's children and the points held in the node's children's children (and so forth). For the purposes of clarity in all discussions about trees, care is taken to differentiate the terms "descendant point" and "point".
Now, it's also important to note that a point does not need to hold any children, and that a node can hold the same points as its children (or its parent). Some types of trees do this. For instance, each node in the cover tree holds only one point, and may have a child that holds the same point. As another example, the 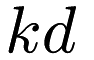 -tree holds its points only in the leaves (at the bottom of the tree). More information on space trees can be found in either the "Tree-independent dual-tree algorithms" paper or any of the related literature.
-tree holds its points only in the leaves (at the bottom of the tree). More information on space trees can be found in either the "Tree-independent dual-tree algorithms" paper or any of the related literature.
So there is a huge amount of possible variety in the types of trees that can fall into the class of space trees. Therefore, it's important to treat them abstractly, and the TreeType policy allows us to do just that. All we need to remember is that a node in a tree can be represented as the combination of some points held in the node, some child nodes, and some geometric structure that represents the space that all of the descendant points fall into (this is a restatement of the fourth part of the definition).
Template parameters required by the TreeType policy
Most everything in mlpack is decomposed into a series of configurable template parameters, and trees are no exception. In order to ease usage of high-level mlpack algorithms, each TreeType itself must be a template class taking three parameters:
MetricType– the underlying metric that the tree will be built on (see the MetricType policy documentation)StatisticType– holds any auxiliary information that individual algorithms may needMatType– the type of the matrix used to represent the data
The reason that these three template parameters are necessary is so that each TreeType can be used as a template template parameter, which can radically simplify the required syntax for instantiating mlpack algorithms. By using template template parameters, a user needs only to write
as opposed to the far more complicated alternative, where the user must specify the values of each template parameter of the tree type:
Unfortunately, the price to pay for this user convenience is that every TreeType must have three template parameters, and they must be in exactly that order. Fortunately, there is an additional benefit: we are guaranteed that the tree is built using the same metric as the method (that is, a user can't specify different metric types to the algorithm and to the tree, which they can without template template parameters).
There are two important notes about this:
- Not every possible input of MetricType, StatisticType, and/or MatType necessarily need to be valid or work correctly for each type of tree. For instance, the QuadTree is limited to Euclidean metrics and will not work otherwise. Either compile-time static checks or detailed documentation can help keep users from using invalid combinations of template arguments.
- Some types of trees have more template parameters than just these three. One example is the generalized binary space tree, where the bounding shape of each node is easily made into a fourth template parameter (the
BinarySpaceTreeclass calls this theBoundTypeparameter), and the procedure used to split a node is easily made into a fifth template parameter (theBinarySpaceTreeclass calls this theSplitTypeparameter). However, the syntax of template template parameters requires that the class only has the correct number of template parameters—no more, no less. Fortunately, C++11 allows template typedefs, which can be used to provide partial specialization of template classes:
Now, the MeanSplitKDTree class has only three template parameters and can be used as a TreeType policy class in various mlpack algorithms. Many types of trees in mlpack have more than three template parameters and rely on template typedefs to provide simplified TreeType interfaces.
The TreeType API
As a result of the definition of space tree in the previous section, a simplified API presents itself quite easily. However, more complex functionality is often necessary in mlpack, so this leads to more functions being necessary for a class to satisfy the TreeType policy. Combining this with the template parameters required for trees given in the previous section gives us the complete API required for a class implementing the TreeType policy. Below is the minimal set of functions required with minor documentation for each function. (More extensive documentation and explanation is given afterwards.)
Although this is significantly more complex than the four-item definition of space tree* might suggest, it turns out many of these methods are not difficult to implement for most reasonable tree types. It is also important to realize that this is a minimum API; you may implement more complex tree types at your leisure (and you may include more template parameters too, though you will have to use template typedefs to provide versions with three parameters; see the previous section).
Before diving into the detailed documentation for each function, let us consider a few important points about the implications of this API:
- Trees are not default-constructible and should not (in general) provide a default constructor. This helps prevent invalid trees. In general, any instantiated mlpack object should be valid and ready to use—and a tree built on no points is not valid or ready to use.
- Trees only need to provide batch constructors. Although many tree types do have algorithms for incremental insertions, in mlpack this is not required because the tree-based algorithms that mlpack implements generally assume fully-built, non-modifiable trees. For this purpose, batch construction is perfectly sufficient. (It's also worth pointing out that for some types of trees, like kd-trees, the cost of a handful of insertions often outweighs the cost of completely rebuilding the tree.)
- Trees must provide a number of distance bounding functions. The utility of trees generally stems from the ability to place quick bounds on distance-related quantities. For instance, if all the descendant points of a node are bounded by a ball of radius
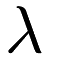 and the center of the node is a point
and the center of the node is a point 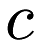 , then the minimum distance between some point
, then the minimum distance between some point 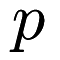 and any descendant point of the node is equal to the distance between and minus the radius :
and any descendant point of the node is equal to the distance between and minus the radius : 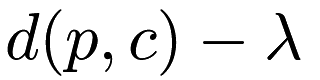 . This is a fast calculation, and (usually) provides a decent bound on the minimum distance between and any descendant point of the node.
. This is a fast calculation, and (usually) provides a decent bound on the minimum distance between and any descendant point of the node. - Trees need to be able to be serialized. mlpack uses the cereal library for saving and loading objects. Trees—which can be a part of machine learning models—therefore must have the ability to be saved and loaded. Making this all work requires a protected constructor (part of the API) and generally makes it impossible to hold references instead of pointers internally, because if a tree is loaded from a file then it must own the dataset it is built on and the metric it uses (this also means that a destructor must exist for freeing these resources).
Now, we can consider each part of the API more rigorously.
Rigorous API documentation
This section is divided into five parts:
- Template parameters
- Constructors and destructors
- Basic tree functionality
- Complex tree functionality and bounds
- Serialization
Template parameters
An earlier section discussed the three different template parameters that are required by the TreeType policy.
The MetricType policy provides one method that will be useful for tree building and other operations:
Note that this method is not necessarily static, so a MetricType object should be held internally and its Evaluate() method should be called whenever the distance between two points is required. It is generally a bad idea to hardcode any distance calculation in your tree. This will make the tree unable to generalize to arbitrary metrics. If your tree must depend on certain assumptions holding about the metric (i.e. the metric is a Euclidean metric), then make that clear in the documentation of the tree, so users do not try to use the tree with an inappropriate metric.
The second template parameter, StatisticType, is for auxiliary information that is required by certain algorithms. For instance, consider an algorithm which repeatedly uses the variance of the descendant points of a node. It might be tempting to add a Variance() method to the required TreeType API, but this quickly leads to code bloat (after all, the API already has quite enough functions as it is). Instead, it is better to create a StatisticType class which provides the Variance() method, and then call Stat().Variance() when the variance is required. This also holds true for cached data members.
Each node should have its own instance of a StatisticType class. The StatisticType must provide the following constructors:
This constructor should be called with (*this) after the node is constructed (usually, this ends up being the last line in the constructor of a node).
The last template parameter is the MatType parameter. This is generally arma::mat or arma::sp_mat, but could be any Armadillo type, including matrices that hold data points of different precisions (such as float or even int). It generally suffices to write MatType assuming that arma::mat will be used, since the vast majority of the time this will be what is used.
Constructors and destructors
The TreeType API requires at least three constructors. Technically, it does not require a destructor, but almost certainly your tree class will be doing some memory management internally and should have one (though not always).
The first two constructors are variations of the same idea:
All that is required here is that a constructor is available that takes a dataset and optionally an instantiated metric. If no metric is provided, then it should be assumed that the MetricType class has a default constructor and a default-constructed metric should be used. The constructor must return a valid, fully-constructed, ready-to-use tree that satisfies the definition of space tree that was given earlier.
It is possible to implement both these constructors as one by using boost::optional.
The third constructor requires the tree to be initializable from a cereal archive:
This has implications on how the tree must be stored. In this case, the dataset is not yet loaded and therefore the tree may be required to have ownership of the data matrix. This means that realistically the most reasonable way to represent the data matrix internally in a tree class is not with a reference but instead with a pointer. If this is true, then a destructor will be required:
and, if the data matrix is represented internally with a pointer, this destructor will need to release the memory for the data matrix (in the case that the tree was created via cereal ).
Note that these constructors are not necessarily the only constructors that a TreeType implementation can provide. One important example of when more constructors are useful is when the tree rearranges points internally; this might be desired for the sake of speed or memory optimization. But to do this with the required constructors would necessarily incur a copy of the data matrix, because the user will pass a "const MatType&". One alternate solution is to provide a constructor which takes an rvalue reference to a MatType:
(and another overload that takes an instantiated metric), and then the user can use std::move() to build the tree without copying the data matrix, although the data matrix will be modified:
It is, of course, possible to add even more constructors if desired.
Basic tree functionality
The basic functionality of a class implementing the TreeType API is quite straightforward and intuitive.
This should return a const reference to the dataset the tree is built on. The fact that this function is required essentially means that each node in the tree must store a pointer to the dataset (this is not the only option, but it is the most obvious option).
Each node must also store an instantiated metric or a pointer to one (note that this is required even for metrics that have no state and have a static Evaluate() function).
As discussed earlier, each node must hold a StatisticType; this is accessible through the Stat() function.
These functions are all fairly self-explanatory. Most algorithms will use the Parent(), Children(), NumChildren(), Point(), and NumPoints() functions, so care should be taken when implementing those functions to ensure they will be efficient. Note that Point() and Descendant() should return indices of points, so the actual points can be accessed by calling "Dataset().col(Point(i))" for some index i (or something similar).
An important note about the Descendant() function is that each descendant point should be unique. So if a node holds the point with index 6 and it has one child that holds the points with indices 6 and 7, then NumDescendants() should return 2, not 3. The ordering in which the descendants are returned can be arbitrary; so, Descendant(0) can return 6 or 7, and Descendant(1) should return the other index.
The last function, Center(), should calculate the center of the bounding shape and store it in the given vector. So, for instance, if the tree is a ball tree, then the center is simply the center of the ball. Algorithm writers would be wise to try and avoid the use of Center() if possible, since it will necessarily cost a copy of a vector.
Complex tree functionality and bounds
A node in a tree should also be able to calculate various distance-related bounds; these are particularly useful in tree-based algorithms. Note that any of these bounds does not necessarily need to be maximally tight; generally it is more important that each bound can be easily calculated.
Details on each bounding function that the TreeType API requires are given below.
Remember that each node corresponds to some region in the space that the dataset lies in. For most tree types this shape is often something geometrically simple: a ball, a cone, a hyperrectangle, a slice, or something similar. The ParentDistance() function should return the distance between the center of this node's region and the center of the parent node's region.
In practice this bound is often used in dual-tree (or single-tree) algorithms to place an easy MinDistance() (or MaxDistance() ) bound for a child node; the parent's MinDistance() (or MaxDistance() ) function is called and then adjusted with ParentDistance() to provide a possibly loose but efficient bound on what the result of MinDistance() (or MaxDistance() ) would be with the child.
It is often very useful to be able to bound the radius of a node, which is effectively what FurthestDescendantDistance() does. Often it is easiest to simply calculate and cache the furthest descendant distance at tree construction time. Some trees, such as the cover tree, are able to give guarantees that the points held in the node will necessarily be closer than the descendant points; therefore, the FurthestPointDistance() function is also useful.
It is permissible to simply have FurthestPointDistance() return the result of FurthestDescendantDistance(), and that will still be a valid bound, but depending on the type of tree it may be possible to have FurthestPointDistance() return a tighter bound.
This is, admittedly, a somewhat complex and weird quantity. It is one of the less important bounding functions, so it is valid to simply return 0...
The bound is a bound on the minimum distance between the center of the node and any edge of the shape that bounds all of the descendants of the node. So, if the bounding shape is a ball (as in a ball tree or a cover tree), then MinimumBoundDistance() should just return the radius of the ball. If the bounding shape is a hypercube (as in a generalized octree), then MinimumBoundDistance() should return the side length divided by two. If the bounding shape is a hyperrectangle (as in a kd-tree or a spill tree), then MinimumBoundDistance() should return half the side length of the hyperrectangle's smallest side.
These six functions are almost without a doubt the most important functionality of a tree. Therefore, it is preferable that these methods be implemented as efficiently as possible, as they may potentially be called many millions of times in a tree-based algorithm. It is also preferable that these bounds be as tight as possible. In tree-based algorithms, these are used for pruning away work, and tighter bounds mean that more pruning is possible.
Of these six functions, there are only really two bounds that are desired here: the minimum distance between a node and an object, and the maximum distance between a node and an object. The object may be either a vector (usually arma::vec ) or another tree node.
Consider the first case, where the object is a vector. The result of MinDistance() needs to be less than or equal to the true minimum distance, which could be calculated as below:
Often the bounding shape of a node will allow a quick calculation that will make a reasonable bound. For instance, if the node's bounding shape is a ball with radius r and center ctr, the calculation is simply "(node.Metric().Evaluate(vec, ctr) - r)". Usually a good MinDistance() or MaxDistance() function will make only one call to the Evaluate() function of the metric.
The RangeDistance() function allows a way for both bounds to be calculated at once. It is possible to implement this as a call to MinDistance() followed by a call to MaxDistance(), but this may incur more metric Evaluate() calls than necessary. Often calculating both bounds at once can be more efficient and can be done with fewer Evaluate() calls than calling both MinDistance() and MaxDistance().
Serialization
The last two public functions that the TreeType API requires are related to serialization and printing.
There are few restrictions on the precise way that the ToString() function should operate, but generally it should behave similarly to the ToString() function in other mlpack methods. Generally, a user will call ToString() when they want to inspect the object and see what it looks like. For a tree, printing the entire tree may be way more information than the user was expecting, so it may be a better option to print either only the node itself or the node plus one or two levels of children.
On the other hand, the specifics of the functionality required for the Serialize() function are somewhat more difficult. The Serialize() function will be called either when a tree is being saved to disk or loaded from disk. The cereal documentation is fairly comprehensive. when writing a Serialize() method for mlpack trees you should use data::CreateNVP() instead of BOOST_SERIALIZATION_NVP(). This is because mlpack classes implement Serialize() instead of serialize() in order to conform to the mlpack style guidelines, and making this work requires some interesting shim code, which is hidden inside of data::CreateNVP(). It may be useful to look at other Serialize() methods contained in other mlpack classes as an example.
An important note is that it is very difficult to use references with cereal, because serialize() may be called at any time during the object's lifetime, and references cannot be re-seated. In general this will require the use of pointers, which then require manual memory management. Therefore, be careful that serialize() (and the tree's destructor) properly handle memory management!
The TreeTraits trait class
Some tree-based algorithms can specialize if the tree fulfills certain conditions. For instance, if the regions represented by two sibling nodes cannot overlap, an algorithm may be able to perform a simpler computation. Based on this reasoning, the TreeTraits trait class (much like the mlpack::kernel::KernelTraits class) exists in order to allow a tree to specify (via a const static bool) when these types of conditions are satisfied. Note that a TreeTraits class is not required, but may be helpful.
The TreeTraits trait class is a template class that takes a TreeType as a parameter, and exposes const static bool values that depend on the tree. Setting these values is achieved by specialization. The code below shows the default TreeTraits values (these are the values that will be used if no specialization is provided for a given TreeType).
An example specialization for the mlpack::tree::KDTree class is given below. Note that mlpack::tree::KDTree is itself a template class (like every class satisfying the TreeType policy), so we are specializing to a template parameter.
Currently, the traits available are each of the five detailed above. For more information, see the mlpack::tree::TreeTraits documentation.
A list of trees in mlpack and more information
mlpack contains several ready-to-use implementations of trees that satisfy the TreeType policy API:
- mlpack::tree::KDTree
- mlpack::tree::MeanSplitKDTree
- mlpack::tree::BallTree
- mlpack::tree::MeanSplitBallTree
- mlpack::tree::RTree
- mlpack::tree::RStarTree
- mlpack::tree::StandardCoverTree
Often, these are template typedefs of more flexible tree classes:
- mlpack::tree::BinarySpaceTree – binary trees, such as the KD-tree and ball tree
- mlpack::tree::RectangleTree – the R tree and variants
- mlpack::tree::CoverTree – the cover tree and variants