


Introduction
Collaborative filtering is an increasingly popular approach for recommender systems. A typical formulation of the problem is as follows: there are 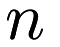 users and
users and 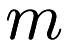 items, and each user has rated some of the items. We want to provide each user with a recommendation for an item they have not rated yet, which they are likely to rate highly. In another formulation, we may want to predict a user's rating of an item. This type of problem has been considered extensively, especially in the context of the Netflix prize. The winning approach for the Netflix prize was a collaborative filtering approach which utilized matrix decomposition. More information on their approach can be found in the following paper:
items, and each user has rated some of the items. We want to provide each user with a recommendation for an item they have not rated yet, which they are likely to rate highly. In another formulation, we may want to predict a user's rating of an item. This type of problem has been considered extensively, especially in the context of the Netflix prize. The winning approach for the Netflix prize was a collaborative filtering approach which utilized matrix decomposition. More information on their approach can be found in the following paper:
The key to this approach is that the data is represented as an incomplete matrix 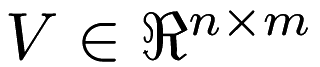 , where
, where 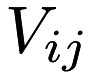 represents user
represents user 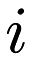 's rating of item
's rating of item 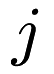 , if that rating exists. The task, then, is to complete the entries of the matrix.
, if that rating exists. The task, then, is to complete the entries of the matrix.
In the matrix factorization framework, the matrix 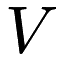 is assumed to be low-rank and decomposed into components as
is assumed to be low-rank and decomposed into components as 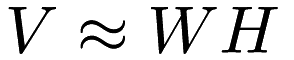 according to some heuristic.
according to some heuristic.
In order to solve problems of this form, mlpack provides:
- a simple command-line interface to perform collaborative filtering
- a simple C++ interface to perform collaborative filtering
- an extensible C++ interface for implementing new collaborative filtering techniques
Table of Contents
- Introduction
- Table of Contents
- The 'mlpack_cf' program
- The 'CF' class
- Template parameters for the 'CF' class
- Further documentation
The 'mlpack_cf' program
mlpack provides a command-line program, mlpack_cf, which is used to perform collaborative filtering on a given dataset. It can provide neighborhood-based recommendations for users. The algorithm used for matrix factorization is configurable, and the parameters of each algorithm are also configurable.
The following examples detail usage of the mlpack_cf program. Note that you can get documentation on all the possible parameters by typing:
Input format for mlpack_cf
The input file for the mlpack_cf program is specified with the –training_file or -t option. This file is a coordinate-format sparse matrix, similar to the Matrix Market (MM) format. The first coordinate is the user id; the second coordinate is the item id; and the third coordinate is the rating. So, for instance, a dataset with 3 users and 2 items, and ratings between 1 and 5, might look like the following:
This dataset has four ratings: user 0 has rated item 1 with a rating of 4; user 1 has rated item 0 with a rating of 5; user 1 has rated item 1 with a rating of 1; and user 2 has rated item 0 with a rating of 2. Note that the user and item indices start from 0, and the identifiers must be numeric indices, and not names.
The type does not necessarily need to be a csv; it can be any supported storage format, assuming that it is a coordinate-format file in the format specified above. For more information on mlpack file formats, see the documentation for mlpack::data::Load().
mlpack_cf with default parameters
In this example, we have a dataset from MovieLens, and we want to use mlpack_cf with the default parameters, which will provide 5 recommendations for each user, and we wish to save the results in the file recommendations.csv. Assuming that our dataset is in the file MovieLens-100k.csv and it is in the correct format, we may use the mlpack_cf executable as below:
The -v option provides verbose output, and may be omitted if desired. Now, for each user, we have recommendations in recommendations.csv:
So, for user 0, the top 5 recommended items that user 0 has not rated are items 317, 422, 482, 356, and 495. For user 5, the recommendations are on the sixth line: 171, 209, 180, 175, 95.
The mlpack_cf program can be built into a larger recommendation framework, with a preprocessing step that can turn user information and item information into numeric IDs, and a postprocessing step that can map these numeric IDs back to the original information.
Saving mlpack_cf models
The mlpack_cf program is able to save a particular model for later loading. Saving a model can be done with the –output_model_file or -M option. The example below builds a CF model on the MovieLens-100k.csv dataset, and then saves the model to the file cf-model.xml for later usage.
The models can also be saved as .bin or .txt; the .xml format provides a human-inspectable format (though the models tend to be quite complex and may be difficult to read). These models can then be re-used to provide specific recommendations for certain users, or other tasks.
Loading mlpack_cf models
Instead of training a model, the mlpack_cf model can also load a model to provide recommendations, using the –input_model_file or -m option. For instance, the example below will load the model from cf-model.xml and then generate 3 recommendations for each user in the dataset, saving the results to recommendations.csv.
Specifying rank of mlpack_cf decomposition
By default, the matrix factorizations in the mlpack_cf program decompose the data matrix into two matrices 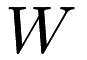 and
and 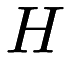 with rank two. Often, this default parameter is not correct, and it makes sense to use a higher-rank decomposition. The rank can be specified with the
with rank two. Often, this default parameter is not correct, and it makes sense to use a higher-rank decomposition. The rank can be specified with the –rank or -R parameter:
In the example above, the data matrix will be decomposed into two matrices of rank 10. In general, higher-rank decompositions will take longer, but will give more accurate predictions.
mlpack_cf with single-user recommendation
In the previous two examples, the output file recommendations.csv contains one line for each user in the input dataset. But often, recommendations may only be desired for a few users. In that case, we can assemble a file of query users, with one user per line:
Now, if we run the mlpack_cf executable with this query file, we will obtain recommendations for users 0, 17, and 31:
mlpack_cf with non-default factorizer
The –algorithm (or -a ) parameter controls the factorizer that is used. Several options are available:
'NMF': non-negative matrix factorization; see mlpack::amf::AMF<>'SVDBatch': SVD batch factorization'SVDIncompleteIncremental': incomplete incremental SVD'SVDCompleteIncremental': complete incremental SVD'RegSVD': regularized SVD; see mlpack::svd::RegularizedSVD
The default factorizer is 'NMF'. The example below uses the 'RegSVD' factorizer:
mlpack_cf with non-default neighborhood size
The mlpack_cf program produces recommendations using a neighborhood: similar users in the query user's neighborhood will be averaged to produce predictions. The size of this neighborhood is controlled with the –neighborhood (or -n ) option. An example using a neighborhood with 10 similar users is below:
The 'CF' class
The CF class in mlpack offers a simple, flexible API for performing collaborative filtering for recommender systems within C++ applications. In the constructor, the CF class takes a coordinate-list dataset and decomposes the matrix according to the specified FactorizerType template parameter.
Then, the GetRecommendations() function may be called to obtain recommendations for certain users (or all users), and the W() and H() matrices may be accessed to perform other computations.
The data which the CF constructor takes should be an Armadillo matrix (arma::mat ) with three rows. The first row corresponds to users; the second row corresponds to items; the third column corresponds to the rating. This is a coordinate list format, like the format the cf executable takes. The data::Load() function can be used to load data.
The following examples detail a few ways that the CF class can be used.
CF with default parameters
This example constructs the CF object with default parameters and obtains recommendations for each user, storing the output in the recommendations matrix.
CF with other factorizers
mlpack provides a number of existing factorizers which can be used in place of the default mlpack::amf::NMFALSFactorizer (which is non-negative matrix factorization with alternating least squares update rules). These include:
- mlpack::amf::SVDBatchFactorizer
- mlpack::amf::SVDCompleteIncrementalFactorizer
- mlpack::amf::SVDIncompleteIncrementalFactorizer
- mlpack::amf::NMFALSFactorizer
- mlpack::svd::RegularizedSVD
- mlpack::svd::QUIC_SVD
The amf::AMF<> class has many other possibilities than those listed here; it is a framework for alternating matrix factorization techniques. See the class documentation or tutorial on AMF for more information.
The use of another factorizer is straightforward; the example from the previous section is adapted below to use svd::RegularizedSVD:
Predicting individual user/item ratings
The Predict() method can be used to predict the rating of an item by a certain user, using the same neighborhood-based approach as the GetRecommendations() function or the cf executable. Below is an example of the use of that function.
The example below will obtain the predicted rating for item 50 by user 12.
Other operations with the W and H matrices
Sometimes, the raw decomposed W and H matrices can be useful. The example below obtains these matrices, and multiplies them against each other to obtain a reconstructed data matrix with no missing values.
Template parameters for the 'CF' class
The CF class takes the FactorizerType as a template parameter to some of its constructors and to the Train() function. The FactorizerType class defines the algorithm used for matrix factorization. There are a number of existing factorizers that can be used in mlpack; these were detailed in the 'other factorizers' example of the previous section.
The FactorizerType class must implement one of the two following methods:
Apply(arma::mat& data, const size_t rank, arma::mat& W, arma::mat& H);Apply(arma::sp_mat& data, const size_t rank, arma::mat& W, arma::mat& H);
The difference between these two methods is whether arma::mat or arma::sp_mat is used as input. If arma::mat is used, then the data matrix is a coordinate list with three columns, as in the constructor to the CF class. If arma::sp_mat is used, then a sparse matrix is passed with the number of rows equal to the number of items and the number of columns equal to the number of users, and each nonzero element in the matrix corresponds to a non-missing rating.
The method that the factorizer implements is specified via the FactorizerTraits class, which is a template metaprogramming traits class:
If FactorizerTraits<MyFactorizer>::UsesCoordinateList is true, then CF will try to call Apply() with an arma::mat object. Otherwise, CF will try to call Apply() with an arma::sp_mat object. Specifying the value of UsesCoordinateList is straightforward; provide this specialization of the FactorizerTraits class:
The Apply() function also takes a reference to the matrices W and H. When the Apply() function returns, the input data matrix should be decomposed into these two matrices. W should have number of rows equal to the number of items and number of columns equal to the rank parameter, and H should have number of rows equal to the rank parameter, and number of columns equal to the number of users.
The amf::AMF<> class can be used as a base for factorizers that alternate between updating W and updating H. A useful reference is the AMF tutorial.
Further documentation
Further documentation for the CF class may be found in the complete API documentation. In addition, more information on the AMF class of factorizers may be found in its complete API documentation.