


Introduction
mlpack implements multiple strategies for approximate furthest neighbor search in its mlpack_approx_kfn and mlpack_kfn programs (each program corresponds to different techniques). This tutorial discusses what problems these algorithms solve and how to use each of the techniques that mlpack implements.
mlpack implements five approximate furthest neighbor search algorithms:
- brute-force search (in
mlpack_kfn) - single-tree search (in
mlpack_kfn) - dual-tree search (in
mlpack_kfn) - query-dependent approximate furthest neighbor (QDAFN) (in
mlpack_approx_kfn) - DrusillaSelect (in
mlpack_approx_kfn)
These methods are described in the following papers:
The problem of furthest neighbor search is simple, and is the opposite of the much-more-studied nearest neighbor search problem. Given a set of reference points 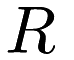 (the set in which we are searching), and a set of query points
(the set in which we are searching), and a set of query points  (the set of points for which we want the furthest neighbor), our goal is to return the
(the set of points for which we want the furthest neighbor), our goal is to return the 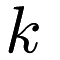 furthest neighbors for each query point in :
furthest neighbors for each query point in :
![\[ \operatorname{k-argmax}_{p_r \in R} d(p_q, p_r). \]](form_180.png)
In order to solve this problem, mlpack provides a number of interfaces.
- two simple command-line executables to calculate approximate furthest neighbors
- a simple C++ class for QDAFN
- a simple C++ class for DrusillaSelect
- a simple C++ class for tree-based and brute-force search
Table of Contents
A list of all the sections this tutorial contains.
- Introduction
- Table of Contents
- Which algorithm should be used?
- Command-line 'mlpack_approx_kfn' and 'mlpack_kfn'
- Calculate 5 furthest neighbors with default options
- Specifying algorithm parameters for DrusillaSelect
- Using QDAFN instead of DrusillaSelect
- Printing results quality with exact distances
- Using cached exact distances for quality results
- Using tree-based approximation with mlpack_kfn
- Different algorithms with 'mlpack_kfn'
- Saving a model for later use
- Final command-line program notes
- DrusillaSelect C++ class
- QDAFN C++ class
- KFN C++ class
- Further documentation
Which algorithm should be used?
There are three algorithms for furthest neighbor search that mlpack implements, and each is suited to a different setting. Below is some basic guidance on what should be used. Note that the question of "which algorithm should be used" is a very difficult question to answer, so the guidance below is just that—guidance—and may not be right for a particular problem.
DrusillaSelectis very fast and will perform extremely well for datasets with outliers or datasets with structure (like low-dimensional datasets embedded in high dimensions)QDAFNis a random approach and therefore should be well-suited for datasets with little to no structure- The tree-based approaches (the
KFNclass and themlpack_kfnprogram) is best suited for low-dimensional datasets, and is most effective when very small levels of approximation are desired, or when exact results are desired. - Dual-tree search is most useful when the query set is large and structured (like for all-furthest-neighbor search).
- Single-tree search is more useful when the query set is small.
Command-line 'mlpack_approx_kfn' and 'mlpack_kfn'
mlpack provides two command-line programs to solve approximate furthest neighbor search:
mlpack_approx_kfn, for the QDAFN and DrusillaSelect approachesmlpack_kfn, for exact and approximate tree-based approaches
These two programs allow a large number of algorithms to be used to find approximate furthest neighbors. Note that the mlpack_kfn program is also documented by the Command-Line 'mlpack_knn' section of the NeighborSearch tutorial (k-nearest-neighbors) page, as it shares options with the mlpack_knn program.
Below are several examples of how the mlpack_approx_kfn and mlpack_kfn programs might be used. The first examples focus on the mlpack_approx_kfn program, and the last few show how mlpack_kfn can be used to produce approximate results.
Calculate 5 furthest neighbors with default options
Here we have a query dataset queries.csv and a reference dataset refs.csv and we wish to find the 5 furthest neighbors of every query point in the reference dataset. We may do that with the mlpack_approx_kfn algorithm, using the default of the DrusillaSelect algorithm with default parameters.
Convenient timers for parts of the program operation are printed. The results, saved in n.csv and d.csv, indicate the furthest neighbors and distances for each query point. The row of the output file indicates the query point that the results are for. The neighbors are listed from furthest to nearest; so, the 4th element in the 3rd row of d.csv indicates the distance between the 3rd query point in queries.csv and its approximate 4th furthest neighbor. Similarly, the same element in n.csv indicates the index of the approximate 4th furthest neighbor (with respect to refs.csv).
Specifying algorithm parameters for DrusillaSelect
The -p (–num_projections) and -t (–num_tables) parameters affect the running of the DrusillaSelect algorithm and the QDAFN algorithm. Specifically, larger values for each of these parameters will search more possible candidate furthest neighbors and produce better results (at the cost of runtime). More details on how each of these parameters works is available in the original papers, the mlpack source, or the documentation given by –help.
In the example below, we run DrusillaSelect to find 4 furthest neighbors using 10 tables and 2 points in each table. In this case we have chosen to omit the -n n.csv option, meaning that only the output candidate distances will be written to d.csv.
Using QDAFN instead of DrusillaSelect
The algorithm to be used for approximate furthest neighbor search can be specified with the –algorithm (-a) option to the mlpack_approx_kfn program. Below, we use the QDAFN algorithm instead of the default. We leave the -p and -t options at their defaults—even though QDAFN often requires more tables and points to get the same quality of results.
Printing results quality with exact distances
The mlpack_approx_kfn program can calculate the quality of the results if the –calculate_error (-e) flag is specified. Below we use the program with its default parameters and calculate the error, which is displayed in the output. The error is only calculated for the furthest neighbor, not all k; therefore, in this example we have set -k to 1.
Note that the output includes three lines indicating the error:
In this case, a minimum error of 1 indicates an exact result, and over the entire query set the algorithm has returned a furthest neighbor candidate with maximum error 1.28712.
Using cached exact distances for quality results
However, for large datasets, calculating the error may take a long time, because the exact furthest neighbors must be calculated. Therefore, if the exact furthest neighbor distances are already known, they may be passed in with the –exact_distances_file (-x) option in order to avoid the calculation. In the example below, we assume exact.csv contains the exact furthest neighbor distances. We run the qdafn algorithm in this example.
Note that the -e option must be specified for the -x option have any effect.
Using tree-based approximation with mlpack_kfn
The mlpack_kfn algorithm allows specifying a desired approximation level with the –epsilon (-e) option. The parameter must be greater than or equal to 0 and less than 1. A setting of 0 indicates exact search.
The example below runs dual-tree furthest neighbor search (the default algorithm) with the approximation parameter set to 0.5.
Note that the format of the output files d.csv and n.csv are the same as for mlpack_approx_kfn.
Different algorithms with 'mlpack_kfn'
The mlpack_kfn program offers a large number of different algorithms that can be used. The –algorithm (-a) may be used to specify three main different algorithm types: naive (brute-force search), single_tree (single-tree search), dual_tree (dual-tree search, the default), and greedy ("defeatist" greedy search, which goes to one leaf node of the tree then terminates). The example below uses single-tree search to find approximate neighbors with epsilon set to 0.1.
Saving a model for later use
The mlpack_approx_kfn and mlpack_kfn programs both allow models to be saved and loaded for future use. The –output_model_file (-M) option allows specifying where to save a model, and the –input_model_file (-m) option allows a model to be loaded instead of trained. So, if you specify –input_model_file then you do not need to specify –reference_file (-r), –num_projections (-p), or –num_tables (-t).
The example below saves a model with 10 projections and 5 tables. Note that neither –query_file (-q) nor -k are specified; this run only builds the model and saves it to model.bin.
Now, with the model saved, we can run approximate furthest neighbor search on a query set using the saved model:
These options work in the same way for both the mlpack_approx_kfn and mlpack_kfn programs.
Final command-line program notes
Both the mlpack_kfn and mlpack_approx_kfn programs contain numerous options not fully documented in these short examples. You can run each program with the –help (-h) option for more information.
DrusillaSelect C++ class
mlpack provides a simple DrusillaSelect C++ class that can be used inside of C++ programs to perform approximate furthest neighbor search. The class has only one template parameter—MatType—which specifies the type of matrix to be use. That means the class can be used with either dense data (of type arma::mat) or sparse data (of type arma::sp_mat).
The following examples show simple usage of this class.
Approximate furthest neighbors with defaults
The code below builds a DrusillaSelect model with default options on the matrix dataset, then queries for the approximate furthest neighbor of every point in the queries matrix.
At the end of this code, both the distances and neighbors matrices will have number of columns equal to the number of columns in the queries matrix. So, each column of the distances and neighbors matrices are the distances or neighbors of the corresponding column in the queries matrix.
Custom numbers of tables and projections
The following example constructs a DrusillaSelect model with 10 tables and 5 projections. Once that is done it performs the same task as the previous example.
Accessing the candidate set
The DrusillaSelect algorithm merely scans the reference set and extracts a number of points that will be queried in a brute-force fashion when the Search() method is called. We can access this set with the CandidateSet() method. The code below prints the fifth point of the candidate set.
Retraining on a new reference set
It is possible to retrain a DrusillaSelect model with new parameters or with a new reference set. This is functionally equivalent to creating a new model. The example code below creates a first DrusillaSelect model using 3 tables and 10 projections, and then retrains this with the same reference set using 10 tables and 3 projections.
Running on sparse data
We can set the template parameter for DrusillaSelect to arma::sp_mat in order to perform furthest neighbor search on sparse data. This code below creates a DrusillaSelect model using 4 tables and 6 projections with sparse input data, then searches for 3 approximate furthest neighbors.
QDAFN C++ class
mlpack also provides a standalone simple QDAFN class for furthest neighbor search. The API for this class is virtually identical to the DrusillaSelect class, and also has one template parameter to specify the type of matrix to be used (dense or sparse or other).
The following subsections demonstrate usage of the QDAFN class in the same way as the previous section's examples for DrusillaSelect.
Approximate furthest neighbors with defaults
The code below builds a QDAFN model with default options on the matrix dataset, then queries for the approximate furthest neighbor of every point in the queries matrix.
At the end of this code, both the distances and neighbors matrices will have number of columns equal to the number of columns in the queries matrix. So, each column of the distances and neighbors matrices are the distances or neighbors of the corresponding column in the queries matrix.
Custom numbers of tables and projections
The following example constructs a QDAFN model with 15 tables and 30 projections. Once that is done it performs the same task as the previous example.
Accessing the candidate set
The QDAFN algorithm scans the reference set, extracting points that have been projected onto random directions. Each random direction corresponds to a single table. The QDAFN class stores these points as a vector of matrices, which can be accessed with the CandidateSet() method. The code below prints the fifth point of the candidate set of the third table.
Retraining on a new reference set
It is possible to retrain a QDAFN model with new parameters or with a new reference set. This is functionally equivalent to creating a new model. The example code below creates a first QDAFN model using 10 tables and 40 projections, and then retrains this with the same reference set using 15 tables and 25 projections.
Running on sparse data
We can set the template parameter for QDAFN to arma::sp_mat in order to perform furthest neighbor search on sparse data. This code below creates a QDAFN model using 20 tables and 60 projections with sparse input data, then searches for 3 approximate furthest neighbors.
KFN C++ class
The extensive NeighborSearch class also provides a way to search for approximate furthest neighbors using a different, tree-based technique. For full documentation on this class, see the NeighborSearch tutorial. The KFN class is a convenient typedef of the NeighborSearch class that can be used to perform the furthest neighbors task with kd-trees.
In the following subsections, the KFN class is used in short code examples.
Simple furthest neighbors example
The KFN class has construction semantics similar to DrusillaSelect and QDAFN. The example below constructs a KFN object (which will build the tree on the reference set), but note that the third parameter to the constructor allows us to specify our desired level of approximation. In this example we choose epsilon = 0.05. Then, the code searches for 3 approximate furthest neighbors.
Retraining on a new reference set
Like the QDAFN and DrusillaSelect classes, the KFN class is capable of retraining on a new reference set. The code below demonstrates this.
Searching in single-tree mode
The particular mode to be used in search can be specified in the constructor. In this example, we use single-tree search (as opposed to the default of dual-tree search).
Searching in brute-force mode
If desired, brute-force search ("naive search") can be used to find the furthest neighbors; however, the result will not be approximate—it will be exact (since every possibility will be considered). The code below performs exact furthest neighbor search by using the KFN class in brute-force mode.
Further documentation
For further documentation on the approximate furthest neighbor facilities offered by mlpack, consult the following documentation: