


Introduction
mlpack supports a wide variety of data (including images) and model formats for use in both its command-line programs and in C++ programs using mlpack via the mlpack::data::Load() function. This tutorial discusses the formats that are supported and how to use them.
Table of Contents
This tutorial is split into the following sections:
- Introduction
- Table of Contents
- Data
- Data Formats
- Image Support
- Models
- Final notes
Simple examples to load data in C++
The example code snippets below load data from different formats into an Armadillo matrix object (arma::mat) or model when using C++.
Supported dataset types
Datasets in mlpack are represented internally as sparse or dense numeric matrices (specifically, as arma::mat or arma::sp_mat or similar). This means that when datasets are loaded from file, they must be converted to a suitable numeric representation. Therefore, in general, datasets on disk should contain only numeric features in order to be loaded successfully by mlpack.
The types of datasets that mlpack can load are roughly the same as the types of matrices that Armadillo can load. However, the load functionality that mlpack provides only supports loading dense datasets. When datasets are loaded by mlpack, the file's type is detected using the file's extension. mlpack supports the following file types:
- csv (comma-separated values), denoted by .csv or .txt
- tsv (tab-separated values), denoted by .tsv, .csv, or .txt
- ASCII (raw ASCII, with space-separated values), denoted by .txt
- Armadillo ASCII (Armadillo's text format with a header), denoted by .txt
- PGM, denoted by .pgm
- PPM, denoted by .ppm
- Armadillo binary, denoted by .bin
- Raw binary, denoted by .bin (note: this will be loaded as one-dimensional data, which is likely not what is desired.)
- HDF5, denoted by .hdf, .hdf5, .h5, or .he5 (note: HDF5 must be enabled in the Armadillo configuration)
- ARFF, denoted by .arff (note: this is not supported by all mlpack command-line programs ; see Categorical features and command line programs)
Datasets that are loaded by mlpack should be stored with one row for one point and one column for one dimension. Therefore, a dataset with three two-dimensional points 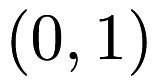 ,
, 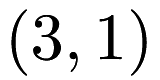 , and
, and 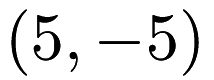 would be stored in a csv file as:
would be stored in a csv file as:
As noted earlier, for command-line programs, the format is automatically detected at load time. Therefore, a dataset can be loaded in many ways:
Similarly, the format to save to is detected by the extension of the given filename.
Loading simple matrices in C++
When C++ is being written, the mlpack::data::Load() and mlpack::data::Save() functions are used to load and save datasets, respectively. These functions should be preferred over the built-in Armadillo .load() and .save() functions.
Matrices in mlpack are column-major, meaning that each column should correspond to a point in the dataset and each row should correspond to a dimension; for more information, see Matrices in mlpack. This is at odds with how the data is stored in files; therefore, a transposition is required during load and save. The mlpack::data::Load() and mlpack::data::Save() functions do this automatically (unless otherwise specified), which is why they are preferred over the Armadillo functions.
To load a matrix from file, the call is straightforward. After creating a matrix object, the data can be loaded:
Saving matrices is equally straightforward. The code below generates a random matrix with 10 points in 3 dimensions and saves it to a file as HDF5.
As with the command-line programs, the type of data to be loaded is automatically detected from the filename extension. For more details, see the mlpack::data::Load() and mlpack::data::Save() documentation.
Dealing with sparse matrices
As mentioned earlier, support for loading sparse matrices in mlpack is not available at this time. To use a sparse matrix with mlpack code, you will have to write a C++ program instead of using any of the command-line tools, because the command-line tools all use dense datasets internally. (There is one exception: the mlpack_cf program, for collaborative filtering, loads sparse coordinate lists.)
In addition, the mlpack::data::Load() function does not support loading any sparse format; so the best idea is to use undocumented Armadillo functionality to load coordinate lists. Suppose you have a coordinate list file like the one below:
This represents a 5x5 matrix with three nonzero elements. We can load this using Armadillo:
The transposition after loading is necessary if the coordinate list is in row-major format (that is, if each row in the matrix represents a point and each column represents a feature). Be sure that the matrix you use with mlpack methods has points as columns and features as rows! See Matrices in mlpack for more information.
Categorical features and command line programs
In some situations it is useful to represent data not just as a numeric matrix but also as categorical data (i.e. with numeric but unordered categories). This support is useful for, e.g., decision trees and other models that support categorical features.
In some machine learning situations, such as, e.g., decision trees, categorical data can be used. Categorical data might look like this (in CSV format):
In the example above, the third dimension (which takes values "true", "false", and "not sure") is categorical. mlpack can load and work with this data, but the strings must be mapped to numbers, because all dataset in mlpack are represented by Armadillo matrix objects.
From the perspective of an mlpack command-line program, this support is transparent; mlpack will attempt to load the data file, and if it detects entries in the file that are not numeric, it will map them to numbers and then print, for each dimension, the number of mappings. For instance, if we run the mlpack_hoeffding_tree program (which supports categorical data) on the dataset above (stored as dataset.csv), we receive this output during loading:
Currently, only the mlpack_hoeffding_tree program supports loading categorical data, and this is also the only program that supports loading an ARFF dataset.
Categorical features and C++
When writing C++, loading categorical data is slightly more tricky: the mappings from strings to integers must be preserved. This is the purpose of the mlpack::data::DatasetInfo class, which stores these mappings and can be used and load and save time to apply and de-apply the mappings.
When loading a dataset with categorical data, the overload of mlpack::data::Load() that takes an mlpack::data::DatasetInfo object should be used. An example is below:
After this load completes, the info object will hold the information about the mappings necessary to load the dataset. It is possible to re-use the DatasetInfo object to load another dataset with the same mappings. This is useful when, for instance, both a training and test set are being loaded, and it is necessary that the mappings from strings to integers for categorical features are identical. An example is given below.
When saving data, pass the same DatasetInfo object it was loaded with in order to unmap the categorical features correctly. The example below demonstrates this functionality: it loads the dataset, increments all non-categorical features by 1, and then saves the dataset with the same DatasetInfo it was loaded with.
There is more functionality to the DatasetInfo class; for more information, see the mlpack::data::DatasetInfo documentation.
Loading and Saving Images
Image datasets are becoming increasingly popular in deep learning.
mlpack's image saving/loading functionality is based on stb/.
Image Utilities API
Image utilities supports loading and saving of images.
It supports filetypes "jpg", "png", "tga", "bmp", "psd", "gif", "hdr", "pic", "pnm" for loading and "jpg", "png", "tga", "bmp", "hdr" for saving.
The datatype associated is unsigned char to support RGB values in the range 1-255. To feed data into the network typecast of arma::Mat may be required. Images are stored in the matrix as (width * height * channels, NumberOfImages). Therefore imageMatrix.col(0) would be the first image if images are loaded in imageMatrix.
Accessing Metadata of Images: ImageInfo
ImageInfo class contains the metadata of the images.
The quality member denotes the compression of the image if it is saved as jpg; it takes values from 0 to 100.
Loading Images in C++
Standalone loading of images.
The example below loads a test image. It also fills up the ImageInfo class object.
ImageInfo requires height, width, number of channels of the image.
More than one image can be loaded into the same matrix.
Loading multiple images:
Saving Images in C++
Save images expects a matrix of type unsigned char in the form (width * height * channels, NumberOfImages). Just like load it can be used to save one image or multiple images. Besides image data it also expects the shape of the image as input (width, height, channels).
Saving one image:
If the matrix contains more than one image, only the first one is saved.
Saving multiple images:
Multiple images are saved according to the vector of filenames specified.
Loading and saving models
Using cereal, mlpack is able to load and save machine learning models with ease. These models can currently be saved in three formats:
- binary (.bin); this is not human-readable, but it is small
- json (.json); this is sort of human-readable and relatively small
- xml (.xml); this is human-readable but very verbose and large
The type of file to save is determined by the given file extension, as with the other loading and saving functionality in mlpack. Below is an example where a dataset stored as TSV and labels stored as ASCII text are used to train a logistic regression model, which is then saved to model.xml.
Many mlpack command-line programs have support for loading and saving models through the –input_model_file (-m) and –output_model_file (-M) options; for more information, see the documentation for each program (accessible by passing –help as a parameter).
Loading and saving models in C++
mlpack uses the cereal library internally to perform loading and saving of models, and provides convenience overloads of mlpack::data::Load() and mlpack::data::Save() to load and save these models.
To be serializable, a class must implement the method
- Note
- For more information on this method and how it works, see the cereal documentation at https://uscilab.github.io/cereal/index.html.
- Examples of serialize() methods can be found in most classes; one fairly straightforward example is found in the mlpack::math::Range class. A more complex example is found in the mlpack::tree::BinarySpaceTree class.
Using the mlpack::data::Load() and mlpack::data::Save() classes is easy if the type being saved has a serialize() method implemented: simply call either function with a filename, a name for the object to save, and the object itself. The example below, for instance, creates an mlpack::math::Range object and saves it as range.txt. Then, that range is loaded from file into another mlpack::math::Range object.
It is important to be sure that you load the appropriate type; if you save, for instance, an mlpack::regression::LogisticRegression object and attempt to load it as an mlpack::math::Range object, the load will fail and an exception will be thrown. (When the object is saved as binary (.bin), it is possible that the load will not fail, but instead load with mangled data, which is perhaps even worse!)
Final notes
If the examples here are unclear, it would be worth looking into the ways that mlpack::data::Load() and mlpack::data::Save() are used in the code. Some example files that may be useful to this end:
- src/mlpack/methods/logistic_regression/logistic_regression_main.cpp
- src/mlpack/methods/hoeffding_trees/hoeffding_tree_main.cpp
- src/mlpack/methods/neighbor_search/knn_main.cpp
If you are interested in adding support for more data types to mlpack, it would be preferable to add the support upstream to Armadillo instead, so that may be a better direction to go first. Then very little code modification for mlpack will be necessary.