


Introduction
The Euclidean Minimum Spanning Tree problem is widely used in machine learning and data mining applications. Given a set 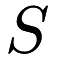 of points in
of points in 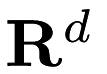 , our task is to compute lowest weight spanning tree in the complete graph on with edge weights given by the Euclidean distance between points.
, our task is to compute lowest weight spanning tree in the complete graph on with edge weights given by the Euclidean distance between points.
Among other applications, the EMST can be used to compute hierarchical clusterings of data. A single-linkage clustering can be obtained from the EMST by deleting all edges longer than a given cluster length. This technique is also referred to as a Friends-of-Friends clustering in the astronomy literature.
mlpack includes an implementation of Dual-Tree Boruvka which uses 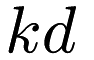 -trees by default; this is the empirically and theoretically fastest EMST algorithm. In addition, the implementation supports the use of different trees via templates. For more details, see the following paper:
-trees by default; this is the empirically and theoretically fastest EMST algorithm. In addition, the implementation supports the use of different trees via templates. For more details, see the following paper:
mlpack provides:
- a simple command-line executable to compute the EMST of a given data set
- a simple C++ interface to compute the EMST
Table of Contents
A list of all the sections this tutorial contains.
- Introduction
- Table of Contents
- Command-Line 'EMST'
- The 'DualTreeBoruvka' class
- Further documentation
Command-Line 'EMST'
The mlpack_emst executable in mlpack will compute the EMST of a given set of points and store the resulting edge list to a file.
The output file contains an edge list representation of the MST in an 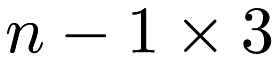 matrix, where the first and second columns are labels of points and the third column is the edge weight. The edges are sorted in order of increasing weight.
matrix, where the first and second columns are labels of points and the third column is the edge weight. The edges are sorted in order of increasing weight.
Below are several examples of simple usage (and the resultant output). The -v option is used so that verbose output is given. Further documentation on each individual option can be found by typing
The code performs at most 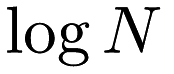 iterations for
iterations for 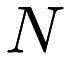 data points. It will print an update on the number of MST edges found after each iteration. Convenient program timers are given for different parts of the calculation at the bottom of the output, as well as the parameters the simulation was run with.
data points. It will print an update on the number of MST edges found after each iteration. Convenient program timers are given for different parts of the calculation at the bottom of the output, as well as the parameters the simulation was run with.
The input points are labeled 0-5. The output tells us that the MST connects point 0 to point 3, point 4 to point 5, point 1 to point 3, point 1 to point 2, and point 2 to point 4, with the corresponding edge weights given in the third column. The total length of the MST is also given in the verbose output.
Note that it is also possible to compute the EMST using a naive ( 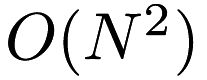 ) algorithm for timing and comparison purposes, using the
) algorithm for timing and comparison purposes, using the –naive option.
The 'DualTreeBoruvka' class
The 'DualTreeBoruvka' class contains our implementation of the Dual-Tree Boruvka algorithm.
The class has two constructors: the first takes the data set, constructs the tree (where the type of tree constructed is the TreeType template parameter), and computes the MST. The second takes data set and an already constructed tree.
The class provides one method that performs the MST computation:
This method stores the computed MST in the matrix results in the format given above.
Further documentation
For further documentation on the DualTreeBoruvka class, consult the complete API documentation.